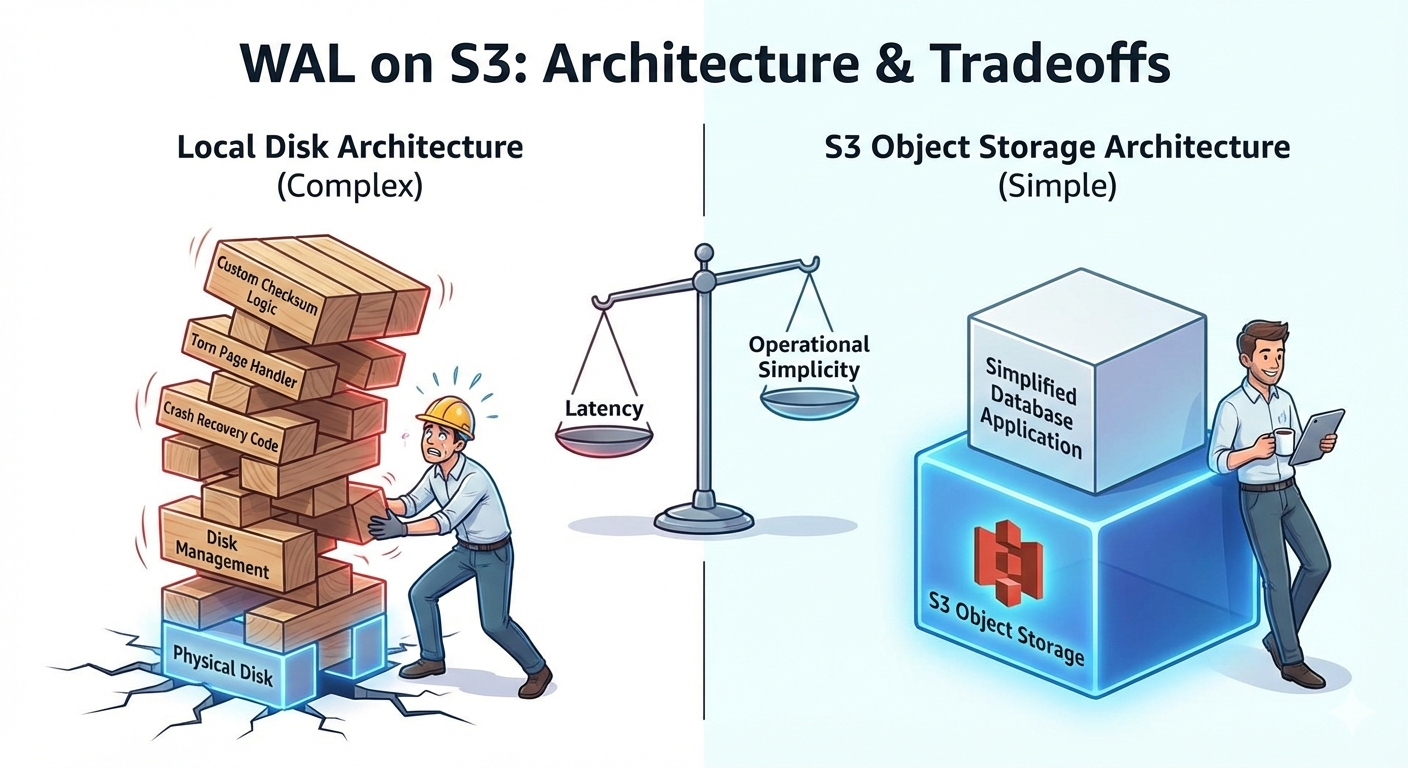
1 Million Rows, 10 Columns, One Table, No Indexes
· 6 min read

Original tweet that inspired this post.
The interesting part of the flat format is that BulkMemtable uses a part-based design: incoming batches are stored as sorted Arrow RecordBatches (BulkParts) and merged as needed. After merging, these parts can be encoded into in-memory Parquet (EncodedBulkParts) to reduce memory… pic.twitter.com/VGPGR60FRx
— Greptime (@Greptime) February 26, 2026
GreptimeDB solves the high-cardinality problem by treating millions of time-series as rows in a flat columnar table, using Arrow for fast writes and Parquet for efficient storage.