WAL on S3 — Why Object Storage Simplifies Database Design

WAL on S3: What You Get for Free
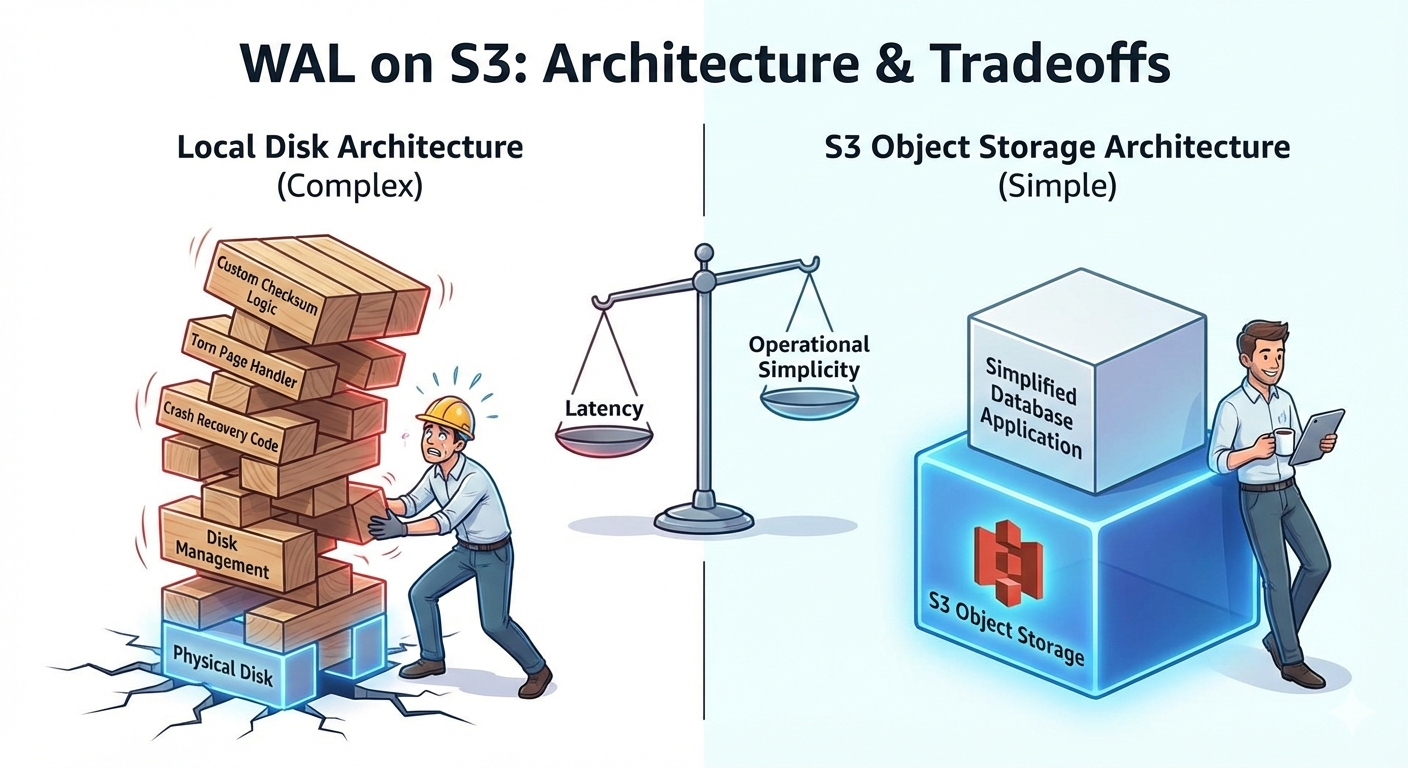
When you build a database on local disk, the WAL (Write-Ahead Log) carries a heavy burden. It must guarantee that committed transactions survive crashes — every write hits the WAL before it touches data files. If the machine loses power mid-write, the WAL is your only path back to a consistent state.
Two hard problems come with building a WAL on local disk:
1. Detecting corrupted records
Every WAL record needs a checksum (Postgres uses CRC-32C). When replaying the log after a crash, the database verifies each record's checksum to detect corruption — a flipped bit, a garbled sector. You have to implement this yourself because local disks offer no integrity guarantees at the application level.
On S3: Object storage handles integrity verification on every read and write. S3 uses internal checksums to detect corruption and heals transparently from redundant copies. You still get to verify on your end if you want (Content-MD5, CRC32C headers), but the storage layer itself won't silently hand you garbage. One less thing to build.
2. Torn pages
This is the subtler problem. Postgres data pages are 8KB. Many storage devices can only atomically write 4KB (one hardware sector) at a time. If power dies after the first 4KB is written but before the second, you get a "torn page" — half new data, half old. The page is internally inconsistent and the checksum won't match either version.
Postgres handles this with full_page_writes: after each checkpoint, the first time a data page is modified, the WAL stores a complete copy of that page. During crash recovery, this full-page image can replace any torn page on disk. It works, but it roughly doubles WAL volume.
On S3: Object writes are all-or-nothing. A PutObject either completes fully and the new object is visible, or it fails and the previous version remains. There is no partial write state. The impedance mismatch between your page size and the storage's atomic write unit simply doesn't exist. No torn pages, no full-page images, no doubled WAL size.
The tradeoff you accept
None of this is free in the latency sense. A local fsync takes microseconds on NVMe. An S3 PutObject takes 10-100ms. For a WAL — where every transaction commit blocks until the write is durable — that's a significant difference. You're trading local-disk write speed for operational simplicity: no torn page handling, no corruption detection code, no disk management, effectively infinite storage, and 11 nines of durability.
Whether that tradeoff is worth it depends on your workload. For OLTP with microsecond commit latency requirements, probably not. For analytical workloads, batch systems, or architectures that can batch WAL writes — it can be a substantial simplification of your storage engine.